![]()
Machine learning (ML) is when algorithms learn from data to find patterns, make decisions and evaluate their performance using a specified dataset. This is useful for applications such as image analysis in remote sensing work. Recently, deep learning - a subclass of ML - has become increasingly popular for image processing and computer vision problems.
While ML models are becoming more utilised across a number of industries, from agriculture to mining, the models can only be as good as the dataset they are trained on. This means that generating a suitable dataset for training an ML model is of the utmost importance.
Let’s look at the process of collecting ML training data and what an ideal dataset looks like in the context of geospatial information systems (GIS) and remote sensing problem-solving applications.
Step 1: Identify your inputs and outputs
The first step towards building an ideal ML model is identifying the available input data sources and desired outputs. The usual input source in remote sensing projects is imagery, either satellite or aerial.
Next, we need to identify the output that we want to get from the ML model.
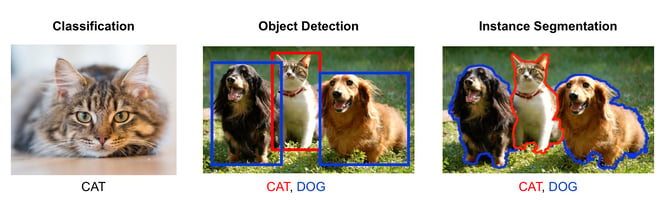
Let’s look at three simple types of image recognition input sources that we can use to base our ML model off, and the outputs they give back:
- Image classification methods that output one class or label per image/tile.
- Object detection methods that only focus on finding and output a bounding box approximation for objects of interest.
- Instance segmentation approaches that classify each pixel in an image to the desired class.
The figure below illustrates the various image recognition approaches:
Step 2: Finalise a training data collection protocol
Once we have shortlisted a ML approach for our project, the next step is to finalise a training data collection protocol. This protocol contains instructions on how to annotate the imagery. For example, if we are to pursue an object detection approach, we will need bounding boxes drawn around the features of interest and a class label assigned to each box.
In the case of image segmentation, we will require precise polygons drawn around the objects of interest. There are a few considerations that should be in place for this step:
- Define a clear and consistent protocol for naming and storing the image files and the corresponding shapefiles.
- Define a clear set of instructions on what does or does not constitute an object of interest. For example, if we want to segment vegetation in Skysat imagery, we will need to manually digitise all the vegetation in an area of interest. Therefore, we must have clear guidelines for this digitisation exercise such as:
- Should there be separate classes for different types of vegetation (eg. grass, bush, trees)?
- Should we include shadows of trees in the tree class?
- How should we deal with ambiguous cases?
- Consistency is key. If there are multiple people working together on a larger area of interest, there will always be inconsistencies as different users have different interpretations of data. Therefore, a quality assurance protocol should be in place.
Step 3: Process the training data for training an ML model
Once we have identified the outcomes of a project and collected a suitable amount of data, we need to convert the dataset into a format that is compatible with our chosen ML model architecture.
Let’s say we want to detect forest logging events using Planetscope imagery. The ML model would need to be trained on a dataset of before and after imagery, along with the identified ground truths of known logging events. When training a change detection model, the input data should be converted to an image pair of before and after rasters and the corresponding ground truth (GT) raster.
The GT raster is a binary raster where 1 represents an occurrence of a logging event and 0 represents no change. The before and after images are 4-band (red, green, blue, and near-infrared) PlanetScope images. The dimensions of the image pairs and the associated GT should be identical. As a result, the input to the deep learning model is an 8-band composite raster along with the GT raster.
Here is an example pair of before and after PlanetScope images with the manually digitised ground truth overlaid on the after image:

What does an ideal ML training dataset look like?
The following characteristics should be represented in the dataset prior to training your ML algorithm:
- Quality: Clean data with no ambiguities.
- Consistency: All the class definitions and digitisations are consistent.
- Quantity: The more, the merrier! Complex problems need more training data.
- Diversity: An ideal dataset should have varied samples of each class under different conditions (such as illumination, weather, etc.).
Want to find out what you can achieve with ML?
You have identified your project’s outcomes and have prepared a decent dataset for it. Get in touch with NGIS to discuss the prospects of using ML for your project.
Back To News Stories